

Long, long ago, in the beginnings of telecom (if you count the “G’s”, maybe in 1G or 2G) we calculate the required network capacity for an specific traffic growth with an erlang table. If you know what is that, chances are that you are as old as me. If you have no idea, better not to use your memory capacity with things that you are not going to use. In a nutshell, the erlang table was used to estimate the traffic that your capacity can absorbed based on a certain blocking probability. The point is that we have an input (traffic) and we got an output (number of HW needed). Time has passed by and that approach is no longer valid. Is not only that the technology has changed, but the tools we have right now are way more powerful. Let me show you how the same problem can be address with Machine Learning techniques.
Frame the problem
If you look for machine learning videos or books, you will probably end up with the house price prediction example, so let’s start with that. Imagine you are a real state agent and you want to predict the price of a house for sale. Let say that you have seen that bigger properties are sell at a higher price than smaller ones, so you draw a chart with the data gathered from previous sales having the square feet in one axis and the sell price in the other. You get something like this:
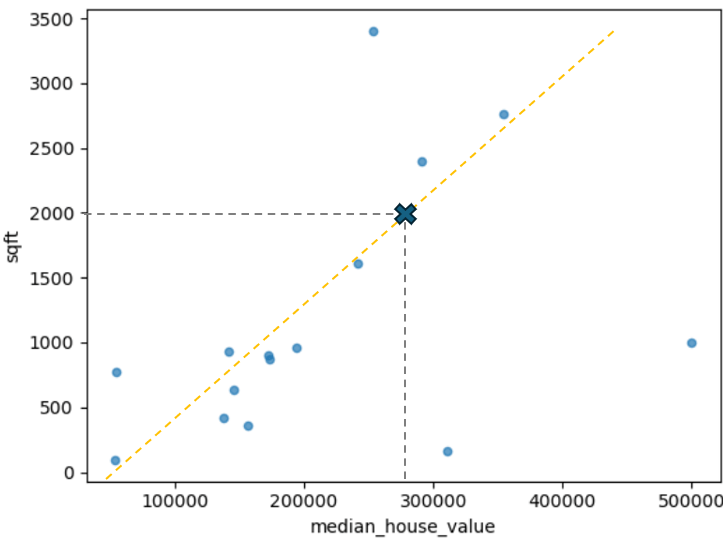
Let’s go a step further and add a trend line, so it can help us with predicting a particular value even if it’s not plotted. For example, we can predict that a house of 20000 sqft will cost around $280,000.00. At this point you might understand that this approach has a lot of missing ends. Just with the data presented you have notice that some properties are very expensive although in size they are small (our hypothesis is false?). Maybe the location or the type of building matters and that is why some properties are that valuable even their size. What about other variables, like if the property is in the coast (beachfront) or is 3 blocks from it? or the amount of bedrooms and rooms (usually same property size with less rooms cost more). You get the point that we need to evaluate multiple variables to solve this issue. Here is where Machine Learning techniques came in.
Going back to predicting capacity/traffic
The same happened with the traffic problem presented at the beginning. Just traffic is not enough to predict the hardware needed. Traffic does not grow the same in cities and in suburban or rural areas. Spectral efficiency (average throughput of each RB) also plays a role; some cells can cope with more users and more payload with the same resources (bandwidth) just because it spectral efficiency is higher. And even the technology is important to consider (4G/5G/IOT) and the carrier number (in case you have multiple carriers). I have just listed few variables that can act as predictors for traffic growth, but surely there are more.
The Machine Learning Project
Where to start? well the first step, that is defining the problem, was approached before. The next steps are the following:
- Define the problem
- Collect & explore data: Here you get the require data from your network (ENIQ, BO, NetAct, PRS and a long etc.). parse it, check for unusual values (nulls and outliers), and perform the exploratory data analysis (EDA).
- Preprocess & clean data: Clean the missing values (or impute them) and deal with outliers. Also is important to normalize/scale numerical values and code categorical ones. Here we can add new features or transform variables, on what is called feature engineering.
- Select & train a model: This is the most interesting part, but in reality it takes just 5% of all the effort.
- Evaluate the model: how good is our model? in our case we are talking about a regression problem (prediction). Normally we use RMSE, MAE and R² to perform model evaluation.
- Improve the model: Check if other models perform better or if there are chances for hyperparameter tuning.
- Deploy the model: In enterprise you will look to deploy as web API for intranet access. Here there are some options like Flask and FastAPI.
- Monitor & maintain: There is always room for automation and tuning.
- Automate your process: I have put this step at the end, but is a very important part indeed. You certainly do not want to this process manually every time you have more data to re-train your model. In serious machine learning projects you have to think that all the above steps have to been done in an automatic way. Here comes the idea of having pipelines concatenated that resolve each of the steps (even gathering the data).
Only for traffic prediction?
Of course that machine learning has plenty of other business cases in the telecom sector. For example you can predict HW failures or even more interesting, when consumers might change to another operator just with radio statistics (and some client data too). We can analyze network complains in advance. And even validate new sites performance (if they are performance compliant or not). So what is the catch? Machine Learning or broadly any data analytics project requires time and effort. Not all managers understand the possibilities that can be discover using these techniques. In my experience, when you talk about machine learning most people in the telecom sector are clueless. This is something that needs to change soon. Else disruption will come from other sectors and the telecom industry will be left behind.
Cheers!
Diego Goncalves Kovadloff
References:
I’m preparing some training on Machine Learning specifically for telecom engineers, but if you are fresh into data analysis, I strongly recommend this course from IBM:
https://skills.yourlearning.ibm.com/ Getting Started with Data

Hello,
Thank you alot for this article, I was looking for someone who uses ML in RF Optimization
Can’t wait for this training
LikeLike
Hello,
Thank you for this article. I’m very interested in applying machine learning and AI algorithms to RF optimization.
I’d be glad to collaborate if you’re interested.
LikeLike